SmolLM3 Small Yet Powerful
A 3B parameter language model that delivers exceptional performance in reasoning, multilingual understanding, and long context processing while maintaining efficiency for edge deployment and resource-conscious applications.
Introduction
Understanding SmolLM3
SmolLM3 represents a significant advancement in small language models, combining compact architecture with powerful capabilities to deliver efficient AI solutions.
SmolLM3 is a state-of-the-art 3 billion parameter language model that demonstrates how smaller models can achieve remarkable performance when designed with precision and trained with care. This model addresses the growing need for efficient AI systems that can operate effectively in resource-constrained environments while maintaining high-quality output across diverse tasks.
The development of SmolLM3 focuses on three core principles: efficiency, capability, and accessibility. Unlike larger models that require substantial computational resources, SmolLM3 is engineered to deliver comparable performance with significantly reduced resource requirements. This makes it particularly suitable for edge computing scenarios, mobile applications, and environments where computational efficiency is paramount.
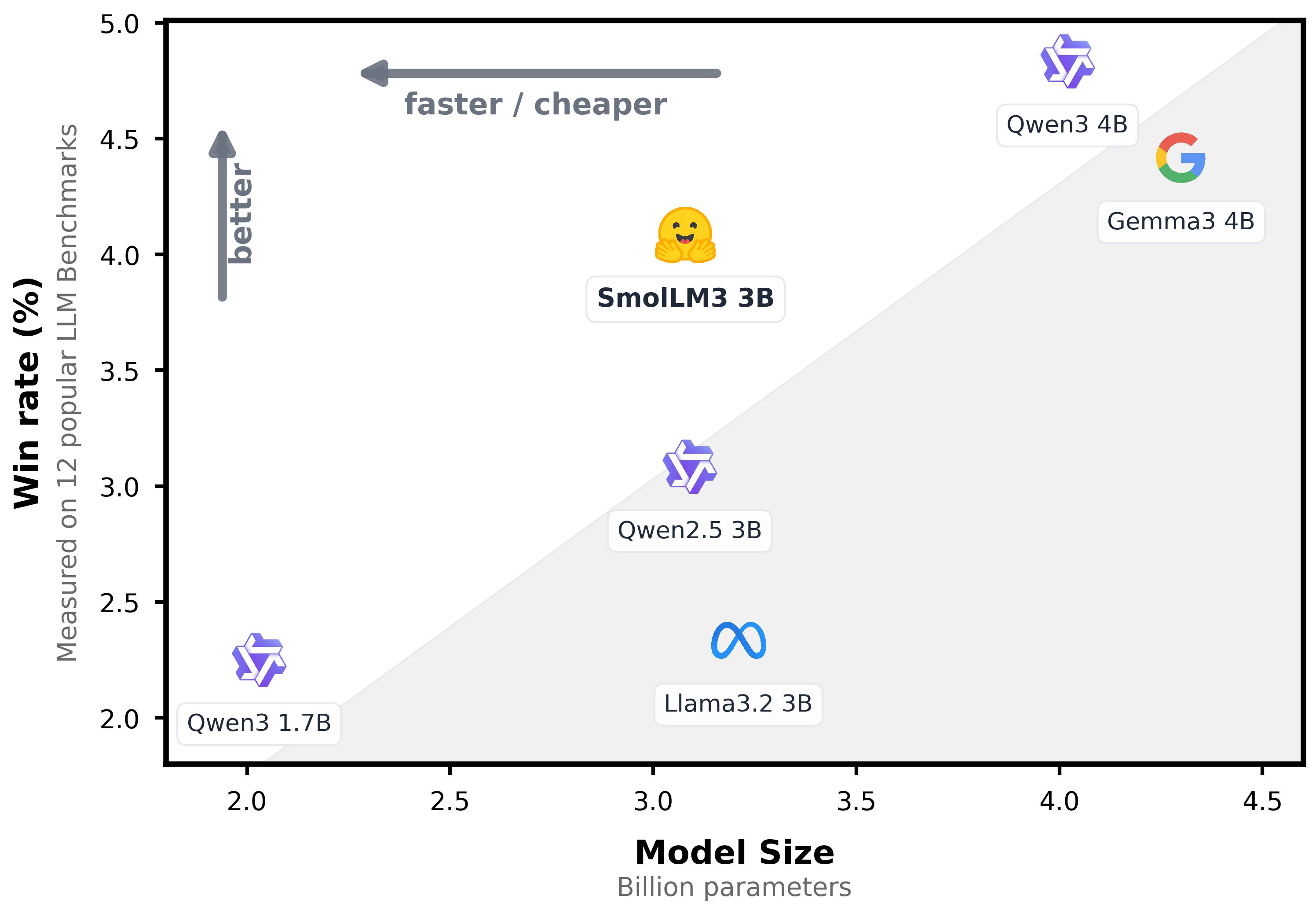
Image credit: https://huggingface.co/HuggingFaceTB/SmolLM3-3B
What sets SmolLM3 apart is its exceptional ability to handle long context windows while maintaining coherent reasoning throughout extended sequences. The model can process and understand relationships across thousands of tokens, making it ideal for applications requiring comprehensive document analysis, extended conversations, and complex reasoning tasks that span multiple paragraphs or pages.
The multilingual capabilities of SmolLM3 extend its utility across global applications. The model demonstrates proficiency in multiple languages, enabling developers to create applications that serve diverse international audiences without requiring separate models for different languages. This multilingual foundation supports both understanding and generation tasks across various linguistic contexts.
Key Features
What Makes SmolLM3 Special
Efficient Performance
Optimized 3B parameter architecture delivers exceptional performance per compute unit, making it ideal for resource-conscious deployments and edge computing scenarios.
Long Context Understanding
Advanced context processing capabilities enable coherent understanding and reasoning across extended documents and complex multi-turn conversations.
Multilingual Support
Comprehensive multilingual capabilities support diverse global applications with consistent performance across multiple languages and cultural contexts.
Technical Capabilities
Advanced Reasoning and Processing
SmolLM3 incorporates sophisticated reasoning mechanisms that enable it to tackle complex analytical tasks with remarkable accuracy. The model's reasoning capabilities extend beyond simple pattern matching to include logical inference, causal understanding, and multi-step problem solving. This makes it particularly effective for applications requiring analytical thinking and structured reasoning.
The model's architecture is optimized for inference efficiency, featuring streamlined attention mechanisms and optimized parameter distributions that maximize performance while minimizing computational overhead. This efficiency translates to faster response times and lower operational costs, making SmolLM3 an attractive option for production deployments where performance and cost-effectiveness are critical considerations.
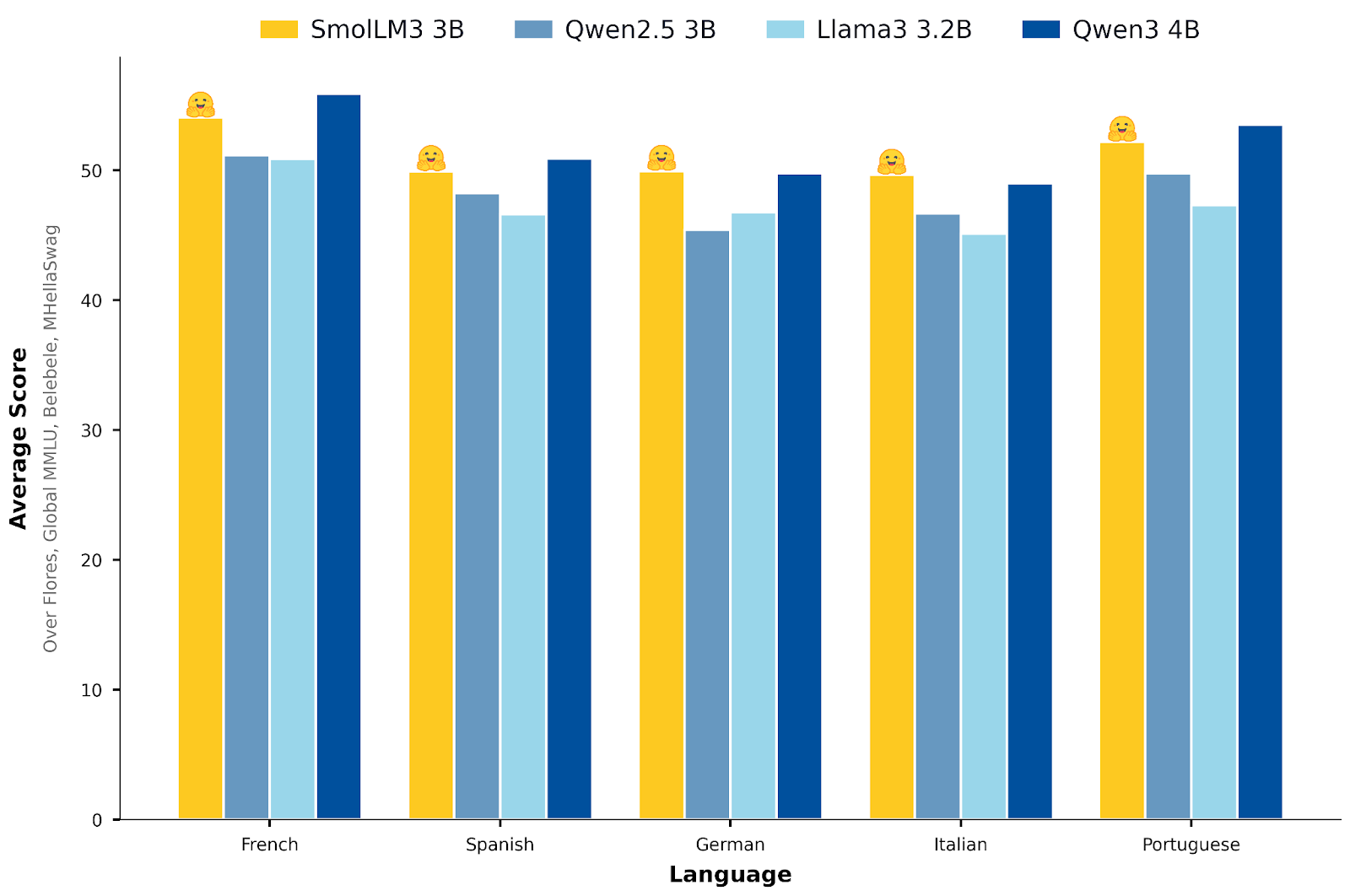
Image credit: https://huggingface.co/HuggingFaceTB/SmolLM3-3B
Memory efficiency is another key strength of SmolLM3. The model's design enables effective processing of large contexts without proportional increases in memory consumption. This efficiency allows for deployment on hardware with limited memory resources while maintaining the ability to process comprehensive inputs and maintain context throughout extended interactions.
The training methodology behind SmolLM3 emphasizes quality over quantity, utilizing carefully curated datasets and advanced training techniques to maximize learning efficiency. This approach results in a model that demonstrates strong generalization capabilities across diverse domains and tasks, reducing the need for extensive fine-tuning for specific applications.
Interactive Demo
Experience SmolLM3 in Action
Try SmolLM3 directly in your browser with this interactive demonstration powered by AnyCoder.
This demo showcases SmolLM3's capabilities through the AnyCoder interface. Experiment with different prompts to see the model's reasoning and generation abilities.
Installation Guide
Run SmolLM3 Locally
Get started with SmolLM3 on your local machine with this step-by-step guide.
Prerequisites
SmolLM3 is available in transformers v4.53.0 or later. Make sure to upgrade your transformers version and install the required dependencies.
pip install -U transformersBasic Usage
Here's a complete example showing how to load and use SmolLM3 for text generation:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# Load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# Prepare the model input
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))Tip: We recommend setting temperature=0.6 and top_p=0.95 in the sampling parameters for optimal results.
Extended Thinking Mode
SmolLM3 features an extended thinking mode that provides reasoning traces. You can control this behavior using system prompts with /think and /no_think flags.
Disabling Extended Thinking
prompt = "Give me a brief explanation of gravity in simple terms."
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)Tool Calling (Agentic Usage)
SmolLM3 supports tool calling functionality. You can pass tools using xml_tools for standard tool-calling or python_tools for Python function calls.
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tools = [
{
"name": "get_weather",
"description": "Get the weather in a city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to get the weather for"
}
}
}
}
]
messages = [
{
"role": "user",
"content": "Hello! How is the weather today in Copenhagen?"
}
]
inputs = tokenizer.apply_chat_template(
messages,
enable_thinking=False, # True works as well, your choice!
xml_tools=tools,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt"
)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))Applications
Real-World Use Cases
SmolLM3's versatility makes it suitable for a wide range of applications across industries and use cases. In educational technology, the model can serve as an intelligent tutoring system, providing personalized explanations and adapting to individual learning styles. Its ability to maintain context over long conversations makes it particularly effective for sustained educational interactions.
Content creation represents another significant application area for SmolLM3. The model can assist writers, journalists, and content creators by providing intelligent suggestions, helping with research synthesis, and offering creative input while maintaining consistency with established tone and style guidelines. Its multilingual capabilities extend these benefits to content creation in multiple languages.
In customer service applications, SmolLM3 can power intelligent chatbots and virtual assistants that provide helpful, contextually appropriate responses while maintaining conversation flow across multiple interactions. The model's reasoning capabilities enable it to understand complex customer queries and provide detailed, accurate responses that address underlying concerns.
Research and analysis applications benefit from SmolLM3's ability to process and synthesize information from multiple sources. The model can assist researchers in literature reviews, data analysis interpretation, and hypothesis generation. Its long context capabilities make it particularly valuable for analyzing comprehensive documents and identifying patterns across extensive datasets.
Development and programming assistance represent another key application area. SmolLM3 can help developers with code review, debugging assistance, documentation generation, and architectural guidance. Its understanding of multiple programming languages and development paradigms makes it a valuable tool for software development teams.
Performance
Efficiency Meets Capability
Computational Efficiency
SmolLM3 delivers exceptional performance per computational unit, making it ideal for deployment scenarios where resource efficiency is crucial. The model's optimized architecture ensures minimal latency while maintaining high-quality outputs across diverse tasks and applications.
Benchmark evaluations demonstrate that SmolLM3 achieves competitive performance compared to larger models while requiring significantly fewer computational resources. This efficiency translates to reduced operational costs and faster response times in production environments.
Scalability and Deployment
The model's compact size enables flexible deployment options, from cloud-based services to edge computing environments. SmolLM3 can run effectively on consumer hardware, making advanced AI capabilities accessible to a broader range of applications and developers.
Deployment flexibility extends to various computing environments, including mobile devices, embedded systems, and resource-constrained servers. This versatility enables organizations to integrate SmolLM3 into existing infrastructure without significant hardware upgrades.
Future Development
Continuing Innovation
The development of SmolLM3 represents an ongoing commitment to advancing small language model capabilities while maintaining efficiency and accessibility. Future iterations will continue to push the boundaries of what's possible with compact model architectures, exploring new training methodologies and architectural innovations that further improve performance per parameter.
Research directions include enhanced multimodal capabilities, improved reasoning mechanisms, and expanded multilingual support. These developments will broaden the model's applicability while maintaining its core strengths in efficiency and performance. The focus remains on creating models that democratize access to advanced AI capabilities.
Community feedback and real-world deployment experiences continue to inform development priorities. The model's evolution is guided by practical needs and empirical performance data, ensuring that improvements address genuine user requirements and application scenarios. This user-centric approach drives meaningful advancement in small language model capabilities.
FAQ
Frequently Asked Questions
What are the key advantages of SmolLM3 over larger language models?
SmolLM3 offers significantly lower computational requirements, faster inference times, and reduced memory usage while maintaining competitive performance. It can run efficiently on edge devices, mobile platforms, and resource-constrained environments where larger models would be impractical or impossible to deploy.
What hardware requirements does SmolLM3 have?
SmolLM3 can run on standard CPUs with as little as 4GB of RAM. While GPU acceleration is supported and recommended for optimal performance, it's not required. The model is designed to work efficiently on mobile devices, edge computers, and even some embedded systems with appropriate optimization.
How does SmolLM3 compare to other small language models?
SmolLM3 demonstrates superior performance-per-parameter ratios compared to similar-sized models. It achieves better accuracy on standard benchmarks while maintaining faster inference speeds. The model's architecture improvements and training methodology result in more effective parameter utilization and enhanced reasoning capabilities.
What programming languages and frameworks are supported?
SmolLM3 supports Python, JavaScript, C++, and Java integration. It's compatible with popular frameworks including PyTorch, TensorFlow, Hugging Face Transformers, and ONNX Runtime. REST APIs and WebAssembly deployment options are also available for broader platform compatibility and web integration.
Can SmolLM3 be fine-tuned for specific use cases?
Yes, SmolLM3 supports both full fine-tuning and parameter-efficient methods like LoRA. The model's compact size makes fine-tuning more accessible and cost-effective compared to larger models. Detailed documentation and example scripts are provided to help users adapt the model for domain-specific applications and specialized tasks.
What licensing terms apply to SmolLM3?
SmolLM3 is released under an open-source license that permits both research and commercial use. The model weights, code, and documentation are freely available. For commercial deployments, please review the full license terms to ensure compliance with attribution and distribution requirements.
Ready to explore SmolLM3?
Discover how SmolLM3 can enhance your applications with efficient, powerful AI capabilities.
Try the Demo